昨天向各位介紹了如何安裝Tensorflow & Keras,希望各位都有安裝成功,若不確定有沒有安裝成功可以在Python編輯器內import這兩個函式庫,看看有沒有錯誤,若沒有錯誤代表你的安裝是正確的。
import tensorflow, keras
如果安裝正確的話今天就隨我來建立類神經網路來判斷mnist手寫資料集吧。
今日目標:建立類神經網路進行圖片的分類任務訓練,目的是判斷mnist資料集的圖片代表甚麼數字。
mnist手寫資料集是一個大型的手寫數字數據集,常用於訓練和測試圖像處理和深度學習。其中資料集包含了60,000個訓練影像和10,000個測試影像,每個影像都是28x28個像素,並且有一個對應的0到9的標籤。
可以使用tensorflow.keras去載入這個資料集,其中x_train是圖片訓練資料,shape是 (60000, 28, 28),代表有60000張圖片,每張圖片長寬都是28;y_train是對應的標籤,也就是該圖片代表的數字,shape是 (60000, )代表60000張照片一共對應到60000個標籤。
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
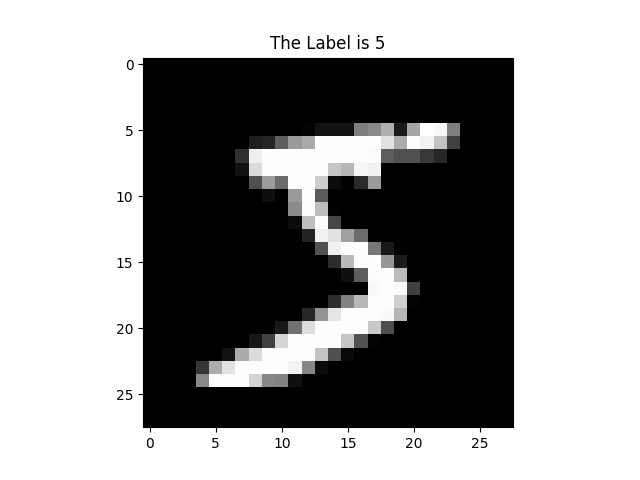
接著我們可以看看這些資料的內容,其中圖片可以使用matplotlib去顯示,matplotlib我在去年有介紹過,顯示圖片資料的程式碼如下:
plt.title(f'The Label is {y_train[0]}') #把第一張照片代表的標籤當作圖片的title
plt.imshow(x_train[0], cmap='gray') #把第一張照片給顯示出來,cmap='gray'代表灰階顯示
plt.show() #顯示圖片
使用plt.imshow(圖片內容, cmap='gray')可以將圖片給顯示出來,圖片內容基本上要是numpy array的格式,shape要是(height, weight, channel),如果要使用彩色圖則要注意圖片的色彩通道為3,此時可以不指定cmap參數。灰階圖片則可以將色彩通道指定為1或者讓圖片維度為二。使用此程式碼就可以看到mnist第一張圖片以及他的標籤。
基本上建立類神經網路分析資料有一些SOP,具體情況還是要根據使用者與實際任務而定,這邊分享我在分析資料時通常會進行的步驟。
載入函式庫
在這步驟我們會載入所有函式庫,並且我習慣把所有要用到的神經網路層 (Layers)都一併載入。Keras已經將Keras神經網路層都整合成一個API,所以要使用會很方便!
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist #資料集
from tensorflow.keras.layers import Input, Conv2D, Flatten, Dense, Activation #神經網路層
from tensorflow.keras.models import Model #類神經網路模型
from tensorflow.keras.optimizers import Adam #優化器
from tensorflow.keras.utils import to_categorical #one-hot轉換
資料預處理 (Data Preprocessing)
這個部分我們要將資料做預處理,所謂預處理就是將這些資料整理成可以輸入到類神經網路模型的格式。以圖像資料來說,以下有幾個簡單的步驟
reshape((60000,28,28,1))將資料塑形。(x_train, y_train), (x_test, y_test) = mnist.load_data()
#訓練資料處理
x_train = x_train/255
x_train = x_train.reshape((60000,28,28,1))
y_train = to_categorical(y_train)
#測試資料處理
x_test = x_test/255
x_test = x_test.reshape((10000,28,28,1))
建立類神經網路
這個步驟我們會建立類神經網路,建立類神經網路也很簡單。指定輸入層、建立隱藏層、輸出層就完成了。接著就是建立模型、編譯模型以及查看模型的資訊 (非必要,但了解自己的模型總是好事)。
指定輸入層顧名思義就是使用Input(shape=(28,28,1)),來指定輸入資料的shape,Keras會自動計算批次量 (batchsize,就是一次要輸入多少筆資料進去模型訓練),所以只需要指定單筆資料、shape即可。
接著就是建立隱藏層,這個模型架構主要由卷積構成,卷積層會指定神經元數量、卷積核大小 (kernel_size)、步進值 (strides)、填充方式 (padding,注意:在使用卷積層時,我們通常會指定padding=“same”,否則圖片的大小會隨著卷積而縮小)。接著輸出會經過激活函數 (Activation),卷積層的激活函數是ReLU函數。接著經過兩層卷積以後會經過展平層 (Flatten)這層會將資料變為一維度的資料,以便輸入至全連接層 (Dense)。
輸出層使用Dense層會指定10個神經元,因為這次的任務是要分類10個類別,激活函數是Softmax,這個函數是計算每個類別的機率是多少。例如三個分類的任務經過Softmax後輸出會變成[0.8, 0.1, 0.1] (當然Dense層要指定3個神經元),代表輸入資料對應到第一個分類的機率最高,接著再去察看第一個分類是甚麼就好。
建立模型會使用model = Model(inputs=input_, outputs=output)來建立模型,此寫法為Functional API,這種寫法可以建立多輸入與多輸出的複雜模型,在未來建立生成模型是必須使用的方式。
編譯模型就是使用model.compile(),在這個函式裡面要指定損失函數(loss)、評估方法(metrics)、優化器(optimizer)。損失函數為交叉熵;評估方法為準確率;優化器則使用Adam,學習率設定0.003。
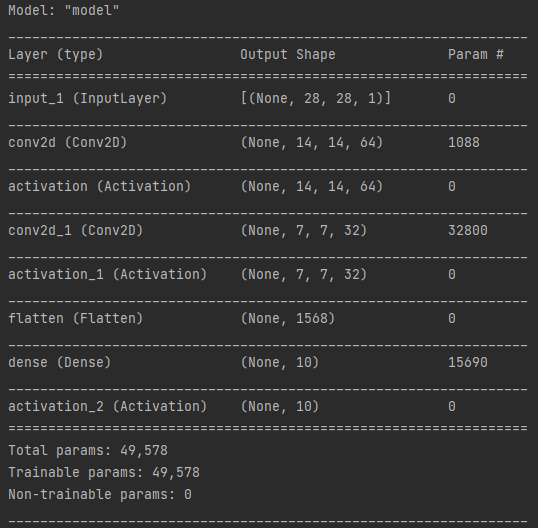
查看模型的資訊即使用model.summary(),這方法可以讓你知道建立的模型大概長甚麼樣子,各網路層輸出張量形狀的資訊。
# 使用Functional API建立模型
input_ = Input(shape=(28,28,1))
x = Conv2D(64, kernel_size=4, strides=2, padding='same')(input_)
x = Activation('relu')(x)
x = Conv2D(32, kernel_size=4, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = Flatten()(x)
x = Dense(10)(x)
output = Activation('softmax')(x)
optimizer = Adam(learning_rate=0.003) #指定優化器
model = Model(inputs=input_, outputs=output) #建立模型
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=optimizer)
#編譯模型,其中要指定損失函數(loss)、評估方法(metrics)、優化器(optimizer)
model.summary() #可以檢視類神經網路模型的資訊:各層的輸出shape與參數量
使用model.summary()時可以在互動視窗看到的模型資訊
訓練類神經網路 (Training)
訓練神經網路只需要使用modl.fit()就好了,意外的簡單呢。不過在這個函式要指定輸入資料 (x_train)與正確答案 (y_train)、訓練次數 (epoch)、訓練批次量 (batchsize),接著拆分測試資料的比例 (validation_split,0.2代表訓練資料中拆20%的資料當作驗證資料)、打亂資料 (shuffle)這兩個設定是非必要的。
history = model.fit(x_train, y_train, epochs=100, batch_size=128,
validation_split=0.2, shuffle=True)
訓練過程可以看到訓練的資訊,如下圖:
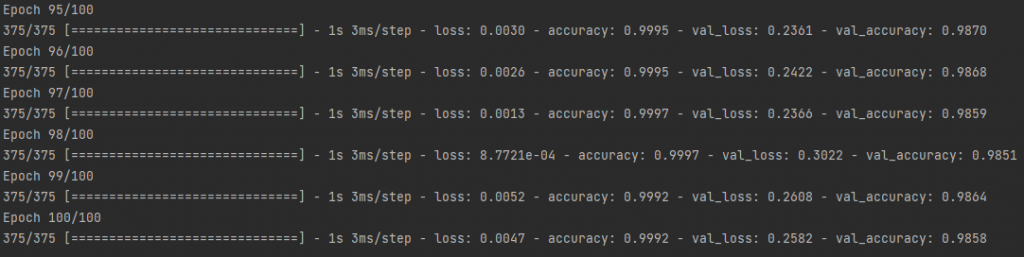
可以看到每次訓練的loss、accuracy、val_loss、val_accuracy,這個就會記錄進訓練歷史 (history)中,作為鍵值 (key),方便之後調用。
評估類神經網路的訓練
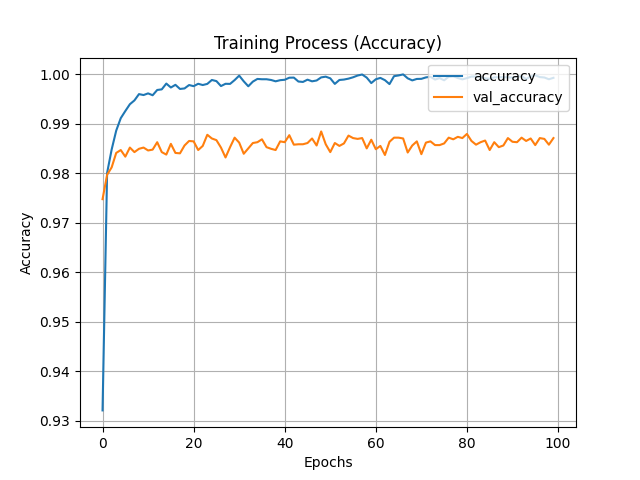
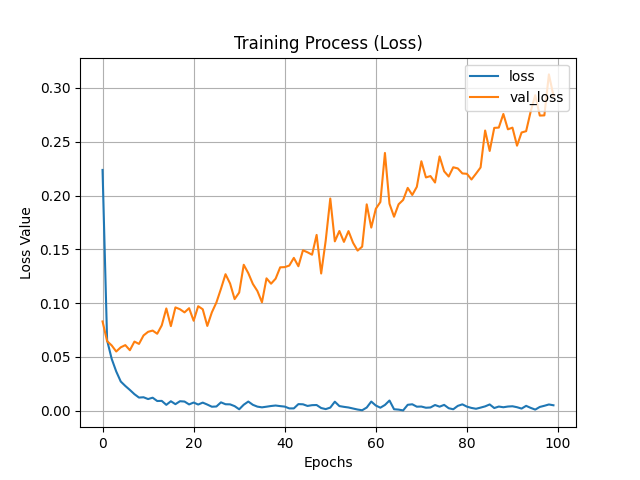
剛剛我們訓練了神經網路模型,接著就是要從訓練歷史中將結果可視化,這可以分析神經網路訓練過程的損失與準確率的變化。需要調用資料則要使用history.history[key]來調用資料,key是上個部分提到的訓練歷史鍵值,為字串格式。
plt.title('Training Process (Accuracy)')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.legend(loc='upper right')
plt.grid(True)
plt.show()
plt.title('Training Process (Loss)')
plt.xlabel('Epochs')
plt.ylabel('Loss Value')
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.legend(loc='upper right')
plt.grid(True)
plt.show()
接著就可以看到隨著訓練,訓練資料與驗證資料之準確率與損失的變化,我們可以看到訓練大約20Epochs時模型準確率就沒有明顯提高了,這很有可能就是模型已經收斂了,此時再提高訓練次數也對訓練無濟於事。另外可以看到損失圖的val_loss隨著訓練提高,這很有可能是訓練有一點過擬合 (over-fitting),此時就要注意可能要縮減訓練次數等,這部分明天會再細講。
今天帶各位使用Keras建立類神經網路並訓練其分類mnist手寫數字資料集,建立神經網路模型其實不難,但要探清其中的門道還是需要化費許多心思。今天藉由建立簡單的模型讓各位知道深度學習的SOP大致為何,未來建立生成模型會比這些模型複雜的多。若各位還有不懂的部分則可以於底下留言詢問,或者去看看其他人所寫的深度學習文章,也可以至書店購買參考書,目前訪間Keras & 深度學習的書非常多,一定有適合各位的~
明天會帶大家分析這個模型的效能,並介紹一些指標,與分析方法。希望大家可以提起精神繼續加油!

